
Alright, so there were many questions and speculations about how Elvenar Spire squad size(s) are calculated. As far as I can tell, the calculation was never disclosed, except for statements that many different things have an impact on that – including total AW levels. But what is the formula? We’ve done a few modeling rounds for specific cases already, and even done a decent general-purpose regression model, but now is the first time when we have come up with a model that might just be a real thing! So, here we go – Model v4.0…
Table of Contents
* – * – *
Previous Work
As I mentioned, we’ve done several modeling rounds already, and a lot of information there is still very much relevant. To avoid copy/pasting ad infinitum, I’ll list previous work here, and may refer to it throughout the text. You almost certainly want to read it beforehand if you haven’t read it already.
- Is here mostly for historical reasons; explains some basics and provides a limited model for the end-of-chapter-15 cities (end-game at the time)
- Our last formula so far, still only for the end-of-chapter-15 cities
Model v2.1
Model v2.1 – Expansions
Model v2.1 – Ancient Wonders
Model v2.1 – Research
Model v2.1 – Misc
- Model v2.1 changes direction of analysis, and effectively lays foundation to Model v3.0. It looks at factors that we deem important for the calculation, and those components are still the same ones that we use in Model v3.0.
- Model v2.1 didn’t provide a specific formula for the Spire squad size, but most of the information and underlying analysis there are still relevant. If you want to understand how Model v3.0 came to be, you definitely want to read up on Model v2.1.
- Model v3.0 was our first general-purpose model, i.e. applicable to any city. Being a pure regression model it was pretty accurate, but the form was quite ugly, and it didn’t cover certain aspects of real-life behavior of Spire squad size (e.g. some research not having any impact).
Data Collection
So over the last few months I’ve been collecting data on the Spire, and now I am running a wider data collection effort. You can contribute to it in the comments below or on the forums here:
Spire squad size calc – we need your data!
The post in the link above also explains what’s needed and how to get it. We need your input! Also, look at this section that further describes what is needed. The more people participate, the faster we can converge to a reasonable model. Hopefully 😉
Definitions
Before we jump into the modeling, let me just say that when I say Spire squad size calculation I mean your own Spire squad size in the very first encounter (e.g. encounter 1 at stage 1 – Gateway). Once you know that number, you can calculate the rest of the Spire squad sizes in all the other encounters (both your own and your enemy’s). I already have that data, and describe it in Spire Requirements Calculation. Here we’ll work on the still unresolved issue of calculating that base Spire squad size number.
Model v4.0
I was contemplating whether to make this iteration v3.x, but ultimately decided that it warrants its own major version. There are certainly some technical differences with Model v3.0, as well as accuracy improvements. But this is not the main reason for the major increment. It is the fact that the new model looks like something designed by a human for the purpose of the Spire squad size calculation. It just makes sense, which is important in model recovery.
Underlying Variables
Before we get to the formula, we need to talk about what are the underlying variables used there. Most are described in more detail in corresponding sections of the Model v2.1, as well as in Model v3.0. But there are certainly differences with the previous version. So here are the variables used:
- M – total number of unlocked mandatory tech items (research)
- A – total number of AW levels
- P – number of placed premium expansions
- V – number of placed non-premium expansions (including initial 6)
Wohoo, we went down from 5 underlying variables down to just 4, and as it turned out we even improved the fit! This is always a good thing 😉 We have dropped regular squad size, and replaced total number of unlocked research items T with total number of unlocked mandatory tech items M. A, P and V variables stay the same as before.
I probably need to clarify what I mean by mandatory tech items. In this context it is simply tech items that have dependent nodes. So if a research item doesn’t have any children, then unlocking it doesn’t impact Spire squad size. We’ll discuss it in more detail in the insights section.
And that’s it, just these 4 parameters can explain most of the variance in the base Spire squad sizes, and do it really, really well. As usual, with the data collected so far 😉
Formula
OK, we all know that this is why you’re here 😉 So:
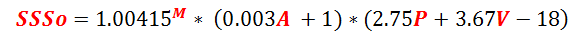
Wait, what? Is that it? It looks almost…nice? So it can’t possibly work well. Or can it? 😉
EDIT: And here is a Google Sheets calculator for the Model v4.0. You’ll need to copy it in order to be able to edit.
Model Accuracy
Well, considering that you’re reading this post, you may suspect that this model actually works. So let’s see (you may need to click in to zoom):

OK, so on this scale there is no real difference with Model v3.0. Both do a very good job at matching values across the whole spectrum. There is nothing that can be gleaned from this chart except that the model works. We need to take a closer look to see the differences. Absolute modeling errors look like this:
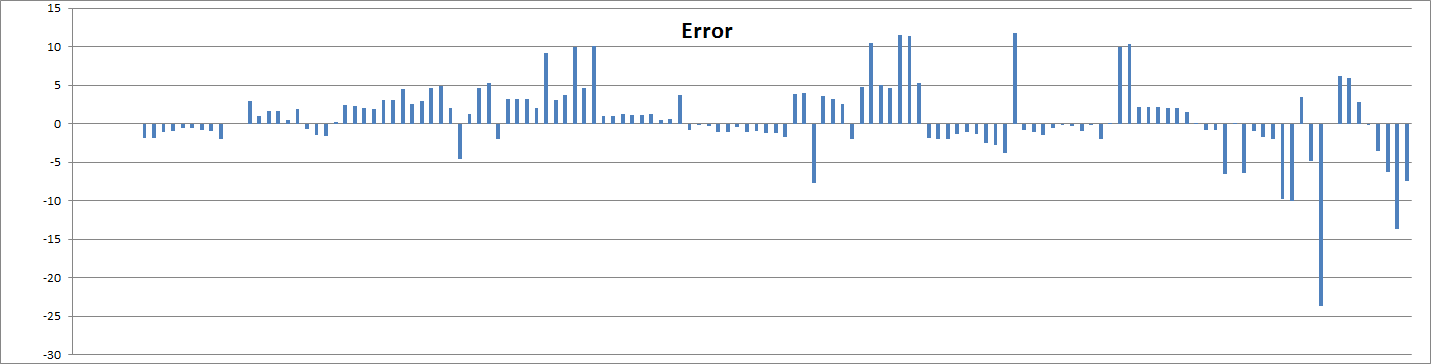
This is… pretty good 😉 I have removed a few outliers that I will discuss later. But here we see that the model predicts results of 100+ observations mostly within +/-10 points. Quite often within 1-2 points even! Remember, this is usually over hundreds or thousands in actual Spire squad size. This is officially amazing! An error in just a single research and/or AW level will be enough to explain pretty much all these deviations, so we’re likely just seeing rounding noise. Seemingly high -23 error is almost exactly corresponding to just 1 difference in M. So in all likelihood it is a measurement error (other points from the same city work quite fine).
And just for kicks let’s look at model errors between v3.0 and v4.0:
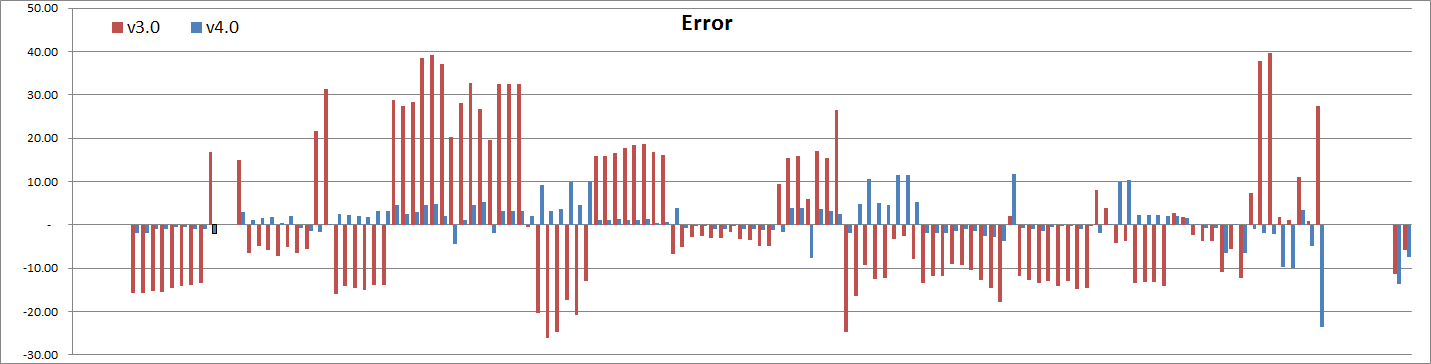
Suffice to say, v4.0 is better across the board. And that’s with less variables to boot. Nice!
Insights
So, is this formula how Spire squad size is calculated? Finally?! Well, for the first time I must say that it looks quite possible. There are only 4 variables, they all make sense, the formula makes sense for something that is actually designed, and the fit is just too good on that many observations to be a fluke.
Model Makes Sense
If you remember, the formula in Model v3.0 was pretty ugly. And as I mentioned, despite a decent fit the original model is unlikely to be designed the way it is in Model v3.0, regardless of numerical parameters. This is a purely regression model, designed to fit observations (even though with some rational choices behind it) – rather than something that would be designed by the game developers.
Now, Model v4.0 changes that. This is a rather simple model (relatively), that looks like something designed by a human. It is factored into independent components corresponding to research, AW levels and expansions, which is what you would do if you design such a thing. And all these components are experimentally confirmed to have an impact on Spire squad size, and we don’t have any other questionable variables in there.
I have also rounded coefficients in Model v4.0 formula to make it more likely to be something designed. There are no weird coefficients here, and all look quite sensible. This means the fit can be even better, but I chose coefficients that make more sense without sacrificing barely any fit.
The formula also avoids negative and zero numbers, which can be a problem with factored formulas. Research term is an exponent, so always >1. AW component is also >= 1 even with zero AWs. Expansion term is >=1 as V is always at least 6 or more. Again, all this makes sense, which is a very good sign.
Better Research Impact
Experimentally, we observed that sometimes unlocking new research doesn’t change Spire SS, and sometimes it does. Model v3.0 doesn’t explain that (outside of rounding errors), but Model v4.0 does by switching from T variable to M variable. It seems that only tech items with child nodes matter, and it is matches experimental observations. The reason why Model v3.0 worked reasonable well even with T variable is because it also had S (regular squad size), and most of the differences between T and M are due to optional squad size upgrades, and S correlates with that. So in effect, Model v3.0 approximated M variable with T and S.
Explains Changes Well
This model also doesn’t seem to exhibit error drift for individual cities, even for several weeks of observations. So it doesn’t match just individual observations, but it also matches changes with evolution of underlying parameters over dozens or hundreds of points in Spire SS changes. This is a very good thing, meaning that this model explains SSS changes due to the observed parameters pretty well.
Model Issues
Now, not everything is peachy here (just most things 😉 ) The formula doesn’t work quite well for very small Spire SS. This is also true for Model v3.0, so it is not worse in that respect, but it is not significantly better either. I don’t have a lot of datapoints there, and the ones I have are not 100% reliable, but it looks that model overestimates SSSo quite a bit for the tiniest of cities:
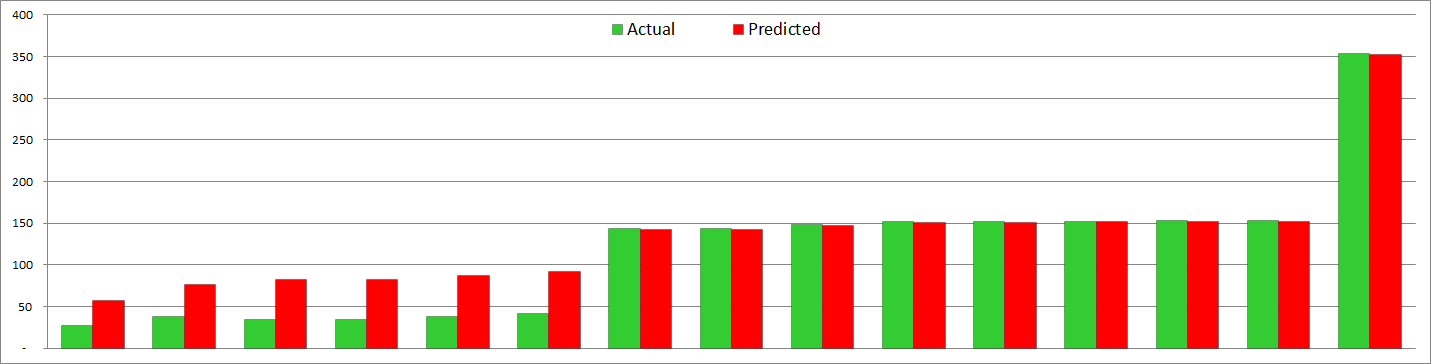
As you can see, the model overestimates the cities with actual SSSo below 50 by almost 2x. And yet with cities at 150 points and all the way up to 9K+ it produces almost perfect results, for every city.
Explanations?
This seems to be related to expansions. Again, given how accurately model predicts results for just about everything else, it is practically impossible to adjust the coefficients in such a way so it only impacts the tiniest cities, but keeps the same fit for everything else.
One explanation might be that there is an explicit and separate adjustment for cities like that. Effectively a bonus reduction in Spire SS if your Spire SS is a small number, or you have a small V, or perhaps even something specific to chapter 3 (both these cities are in chapter 3, while chapter 4 city with 150 points already fits perfectly).
It is also possible that there is some weird rounding and/or cap/flooring going on. This would be, well, weird, but still possible.
To figure this part out, we’ll need to have more observations of the tiniest cities! Ideally with no AWs and no premium expansions. The good news is, these experiments are easier to set up than some with ultra-large cities.
So watch this space, that part is not closed yet. But for the rest, I don’t think we’ll get much better than that, given all the rounding that might be going on. It might be possible to still improve coefficient estimation, but in all likelihood this will only be impactful for super-giant cities. And only if we’ll start seeing some errors creeping up – which right now we don’t.
Interpretation
Now, with the usual disclaimer in place, let’s assume that our model is a real thing. What would that mean?
Multiplication
The fact that research term is a multiplier means that the same changes in other parameters lead to different changes in Spire SS. The more research you’ve done, the higher the impact. We can say the same about AW levels as that term is also a multiplier. Ditto for expansions.
This behavior is certainly that we can see in actual data, so our model explains that.
Research
So the research term (1.00415M) is pretty easy to explain. It basically means that if other parameters stay the same, a single extra unlocked mandatory research will increase your base Spire squad size by 0.415%. That’s it 😉 The model is pretty sensitive to this coefficient, so it is almost certain that this is the right number (given that overall model is correct). Clean experiments also confirm this number.
This also means that amount of KPs in research doesn’t matter. Partially filled research doesn’t matter. Filled but not paid for research doesn’t matter. And research with no dependent nodes doesn’t matter. So from that perspective taking optional SSU techs won’t impact Spire SS at all. But it’s not just optional SSU – any optional research (expansions, culture etc) won’t have an impact.
One interesting observation is that the last research item in the tech tree doesn’t have any dependents, so from that perspective it does NOT count. And right now chapter 16 is the last chapter, and it has 3 final techs. Taking any of those does not change your Spire SS (matches observations so far).
This also means that when chapter 17 tech tree gets populated, some of these final techs may become mandatory automagically, even without doing anything in the city. We may see a jump to Spire SS for end-game cities when chapter 17 gets added (not when city starts playing chapter 17!)
M Values per Chapter
Another interesting thing about this approach is that everyone at the end of each chapter will have the same research multiplier, regardless of which optional techs you did or did not take before that. This also makes sense from the design perspective, so another argument for this being real. You can use the table below to get base M value for your chapter, and then add manually counted number of unlocked mandatory tech items from your current one:
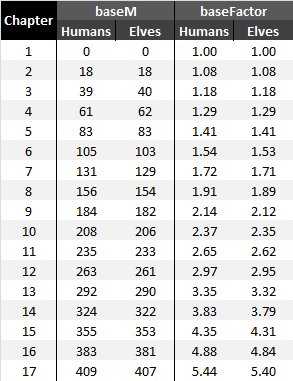
Ancient Wonders
AW term is (0.003A+1), meaning that for every ~333 AW levels you get 1x Spire SS increase. E.g. if your Spire SS with no AWs whatsoever is 1x, then adding ~333 AW levels will double it to 2x, ~667 AW levels will triple it to 3x and 1000 AW levels will quadruple it to 4x. If you keep your research and expansions constant (e.g. end-game), then you will be adding the same points per AW level, on average.
It also means that only total AW levels matter. Kind of AW does not matter. Specific size, level, KP contributions etc do not matter. AWs with KPs contributed but not upgraded do not count as an increase. This generally agrees with experimental observations (with some rounding noise on top).
Expansions
We can also see different coefficients for premium expansions (P) and non-premium expansions (V). This means that adding a single premium expansion increases your Spire SS less than adding a single non-premium expansion. We do see evidence of that in the data.
If you keep your research and AW levels constant, then you will be adding the same points per expansion kind (premium and non-premium differ).
Regular Squad Size
Not a factor anymore! So players who did take optional SSUs are not penalized for that in the Spire at all. Enough said 😉
Other variables
Nothing else has an impact on the Spire squad size. Moving up a chapter doesn’t matter outside of completion of another research item (confirmed experimentally). Main Hall upgrades do not matter (also confirmed experimentally). Number of relics does not matter.
Basically, all kinds of other things that were considered to have an impact do not actually matter.
Conclusion
So we did get a new and improved model this time around. And it even seems to work across the whole spectrum of cities. And predicted results match the observations pretty well. And this time around, it just makes sense. I think we’re almost there!
The only thing that may still need to be explained (outside of keeping validating the model) is behavior for tiniest of cities. There is still something going on there, but it doesn’t seem to have any impact on the rest of the modeling. So realistically, this is only for academic interest. I don’t think many people would care about modeling <50 SSSo cities 😉
So you can already start playing with this formula and see if your city data fits. Most of the parameters are easy to observe, except for the total unlocked mandatory research. I have posted (above) the table of these values for each completed chapter, so you can use that and add manually calculated number from your current chapter. The rest is pretty easy.
So that’s it for now. Let me know in the comments if your city does or does not match well with the model forecast. It would be particularly interesting if it doesn’t, especially if significantly so.
As I said, I think we’re almost there 😉

![Read more about the article Elvenar – Tournament Tutorial [2020] – Planks](https://minmaxgame.com/wp-content/uploads/2020/08/Ett-planks.webp)
![Read more about the article Elvenar Sorcerers & Dragons – Day 12 [40%]](https://minmaxgame.com/wp-content/uploads/2019/04/SDFeaturedD12.webp)
![Read more about the article Elvenar Sorcerers & Dragons – Day 06 [23%]](https://minmaxgame.com/wp-content/uploads/2019/04/SDFeaturedD06.webp)
![Read more about the article Elvenar Woodelves – Day 30 [87%]](https://minmaxgame.com/wp-content/uploads/2019/03/WoodelvesFeaturedD30.webp)
![Read more about the article Elvenar Woodelves – Day 17 [54%]](https://minmaxgame.com/wp-content/uploads/2019/03/WoodelvesFeaturedD17.webp)

You are just Amazing !
Congrats for the hard and successful work 🙂